The AMD Advancing AI & Instinct MI300 Launch Live Blog (Starts at 10am PT/18:00 UTC)

This morning is an important one for AMD – perhaps the most important of the year. After almost a year and a half of build-up, and even longer for actual development, AMD is launching their next generation GPU/APU/AI accelerator family, the Instinct MI300 series. Based on AMD’s new CDNA 3 architecture, and combining it with AMD’s proven Zen 4 cores, AMD will be making a full-court press for the high-end GPU and accelerator market with their new product, aiming to lead in both big-metal HPC as well as the burgeoning market for generative AI training and inference.
Taking the stage for AMD’s launch event will be AMD CEO Dr. LIsa Su, as well as a numerous AMD executives and ecosystem partners, to detail, at last, AMD’s latest generation GPU architecture, and the many forms it will come in. With both the MI300X accelerator and MI300A APU, AMD is aiming to cover most of the accelerator market, whether clients just need a powerful GPU or a tightly-coupled GPU/CPU pairing.
The stakes for today’s announcement are significant. The market for generative AI is all but hardware constrained at the moment, much to the benefit of (and profits for) AMD’s rival NVIDIA. So AMD is hoping to capitalize on this moment to cut off a piece – perhaps a very big piece – of the market for generative AI accelerators. AMD has made breaking into the server space their highest priority over the last half-decade, and now, they believe, is their time to take a big piece of the server GPU market.
12:56PM EST – We’re here in San Jose for AMD’s final and most important launch event of the year: Advancing AI
12:57PM EST – Today AMD is making the eagerly anticipated launch of their next-generation MI300 series of accelerators
12:58PM EST – Including MI300A, their first chiplet-based server APU, and MI300X, their stab at the most powerful GPU/accelerator possible for the AI market
12:59PM EST – I’d say the event is being held in AMD’s backyard, but since AMD sold their campus here in the bay area several years ago, this is more like NVIDIA’s backyard. Which is fitting, given that AMD is looking to capture a piece of the highly profitable Generative AI market from NVIDIA

12:59PM EST – We’re supposed to start at 10am local time here – so in another minute or so
12:59PM EST – And hey, here we go. Right on time
01:00PM EST – Starting with an opening trailer
01:00PM EST – (And joining me on this morning’s live blog is the always-awesome Gavin Bonshor)
01:00PM EST – Advancing AI… together
01:01PM EST – And here’s AMD’s CEO, Dr. Lisa Su
01:01PM EST – Today “is all about AI”

01:01PM EST – And Lisa is diving right in
01:02PM EST – It’s only been just a bit over a year since ChatGPT was launched. And it’s turned the computing industry on its head rather quickly
01:02PM EST – AMD views AI as the single most transformative technology in the last 50 years
01:02PM EST – And with a rather quick adoption rate, despite being at the very beginning of the AI era
01:02PM EST – Lisa’s listing off some of the use cases for AI

01:03PM EST – And the key to it? Generative AI. Which requires significant investments in infrastructure
01:03PM EST – (Which NVIDIA has captured the lion’s share of thus far)

01:03PM EST – In 2023 AMD projected the CAGR for the AI market would be $350B by 2027
01:04PM EST – Now they think it’s going to be $400B+ by 2027

01:04PM EST – A greater than 70% compound annual growth rate
01:04PM EST – AMD’s AI strategy is centered around 3 big strategic priorities

01:05PM EST – A broad hardware portfolio, an open and proven software ecosystem, and partnerships to co-innovate with
01:05PM EST – (AMD has historically struggled with software in particular)
01:05PM EST – Now to products, starting with the cloud
01:06PM EST – Generative AI requires tens of thousands of accelerators at the high-end

01:06PM EST – The more compute, the better the model, the faster the answers
01:06PM EST – Launching today: AMD Instinct MI300X accelerator
01:06PM EST – “Highest performance accelerator in the world for generative AI”

01:07PM EST – CDNA 3 comes wiht a new compute engine, sparsity support, industry-leading memory bandwidth and capacity, etc
01:07PM EST – 3.4x more perf for BF16, 6.8x INT8 perf, 1.6x memory bandwidth

01:07PM EST – 153B transistors for MI300X
01:08PM EST – A dozen 5nm/6nm chiplets
01:08PM EST – 4 I/O Dies in the base layer
01:08PM EST – 256MB AMD Infinity Cache, Infinity Fabric Support, etc
01:08PM EST – 8 XCD compute dies stacked on top
01:08PM EST – 304 CDNA 3 compute units
01:08PM EST – Wired to the IODs via TSVs

01:09PM EST – And 8 stacks of HBM3 attached to the IODs, for 192GB of memory, 5.3 TB/second of bandwidth

01:09PM EST – And immediately jumping to the H100 comparisons
01:10PM EST – AMD has the advantage in memory capacity and bandwidth due to having more HBM stacks. And they think that’s going to help carry them to victory over H100
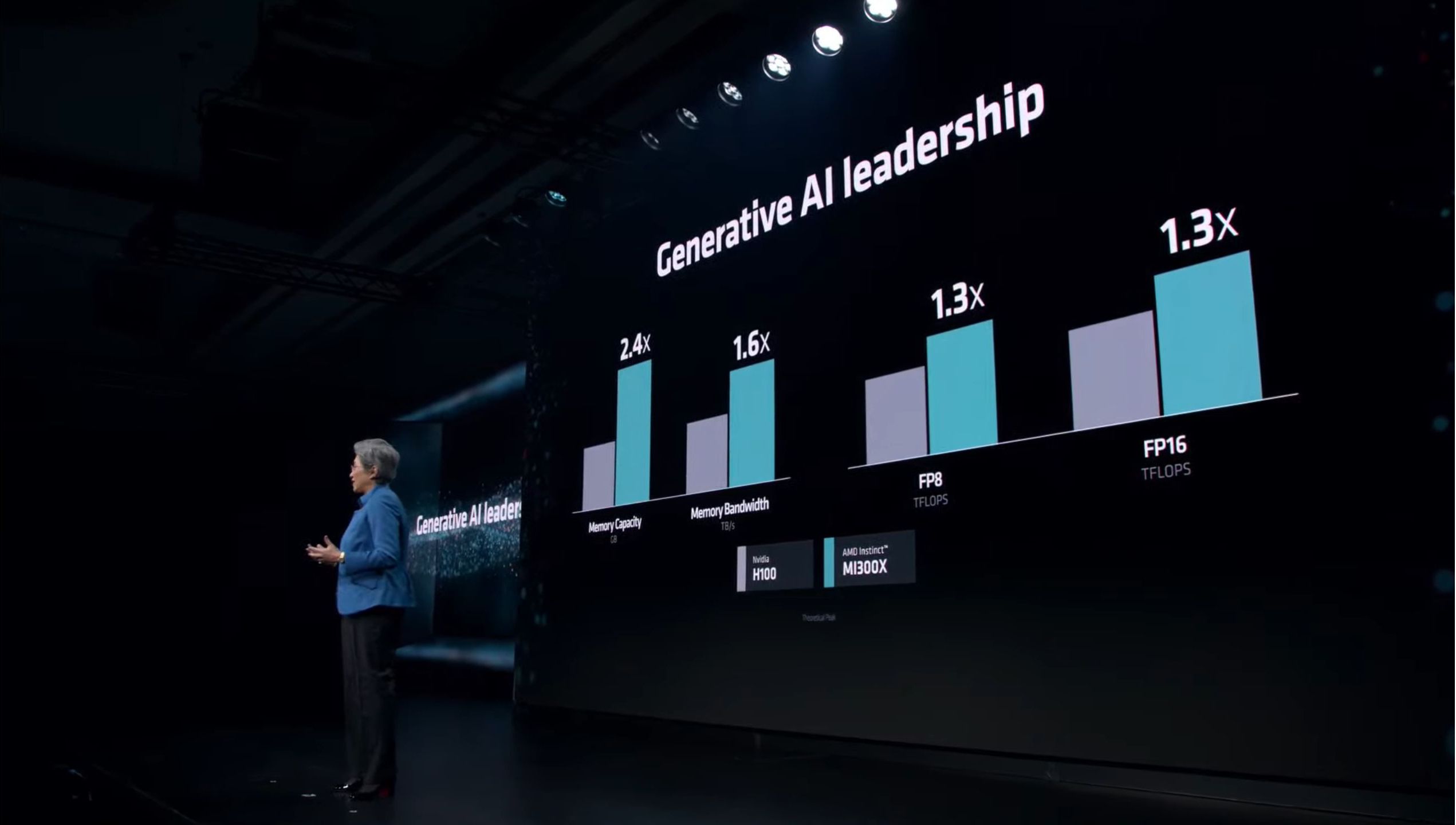
01:10PM EST – AMD finds they have the performance advantage in FlashAttention-2 and Llama 2 70B. At the kernel level in TFLOPS

01:11PM EST – And how does MI300X scale?
01:11PM EST – Comparing a single 8 accelerator server

01:12PM EST – Bloom 176B (throughput) and Llama 2 70B (latency) inference performance.
01:12PM EST – And now AMD’s first guest of many, Microsoft
01:13PM EST – MS CTO, Kevin Scott

01:14PM EST – Lisa is asking Kevin for his thoughts on where the industry is on this AI journey
01:15PM EST – Microsoft and AMD have been building the foundation for several years here

01:16PM EST – And MS will be offering MI300X Azure instances
01:16PM EST – MI300X VMs are available in preview today
01:17PM EST – (So MS apparently already has a meaningful quanity of the accelerators)
01:17PM EST – And that’s MS. Back to Lisa
01:17PM EST – Now talking about the Instinct platform
01:18PM EST – Which is based on an OCP (OAM) hardware design

01:18PM EST – (No fancy name for the platform, unlike HGX)
01:18PM EST – So here’s a whole 8-way MI300X board

01:18PM EST – Can be dropped into almost any OCP-compliant design
01:19PM EST – Making it easy to install MI300X

01:19PM EST – And making a point that AMD supports all of the same I/O and networking capabilities of the competition (but with better GPUs and memory, of course)
01:20PM EST – Customers are trying to maximize not just space, but capital expedetures and operational expedetures as well
01:20PM EST – On the OpEx side, more memory means being able to run either more models or bigger models
01:21PM EST – Which saves on CapEx expenses by buying fewer hardware units overall

01:21PM EST – And now for the next partner, Oracle. Karan Batta, the SVP of Oracle Cloud Infrastructure

01:22PM EST – Oracle is one of AMD’s major cloud computing customers
01:23PM EST – Oracle will be supporting MI300X as part of their bare metal compute offerings
01:23PM EST – And MI300X in a generative AI service that is in the works
01:24PM EST – Now on stage: AMD President Victor Peng to talk about software progress

01:25PM EST – AMD’s software stack is traditionally been their achilles heel, despite efforts to improve it. Peng’s big project has been to finally get things in order
01:25PM EST – Including building a unified AI software stack

01:25PM EST – Today’s focus is on ROCm, AMD’s GPU software stack

01:26PM EST – AMD has firmly attached their horse to open source, which they consider a huge benefit
01:26PM EST – Improving ROCm support for Radeon GPUs continues
01:26PM EST – ROMc 6 shipping later this month

01:27PM EST – It’s been optimized for generative AI, for MI300 and other hardware

01:27PM EST – “ROCm 6 delivers a quantum leap in performance and capability”
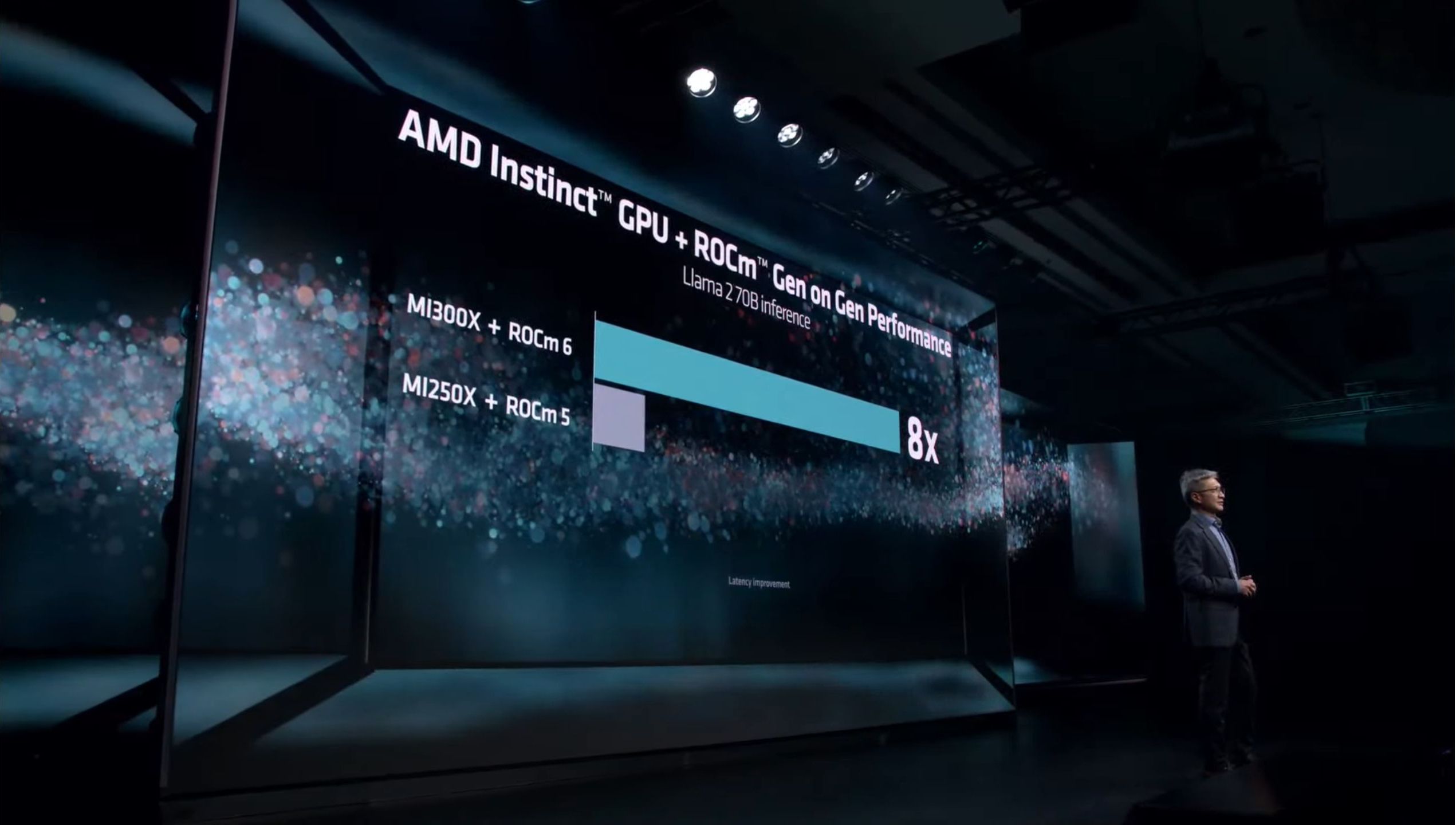
01:28PM EST – Software perf optimization example with LLMs
01:28PM EST – 2.6x from optimized libraries, 1.4x from HIP Graph, etc
01:28PM EST – This, combined with hardware changes, is how AMD is delivering 8x more GenAI perf on MI300X versus MI250 (with ROCm 5)

01:29PM EST – Recapping recent acquisitions as well, such as the nod AI compiler
01:30PM EST – And on the ecosystem level, AMD has an increasing number of partners
01:30PM EST – Hugging Face arguably being the most important, with 62K+ models up and running on AMD hardware

01:31PM EST – AMD GPUs will be supported in the OpenAI Triton 3.0 release

01:32PM EST – Now for more guests: Databricks, Essential AI, and Lamini

01:33PM EST – The four of them are having a short chat about the AI world and their experience with AMD

01:34PM EST – Talking about the development of major tools such as vLLM
01:34PM EST – Cost is a huge driver
01:36PM EST – It was very easy to incluide ROCm in Databricks’ stack
01:36PM EST – Meanwhile Essential AI is taking a full stack approach

01:37PM EST – The ease of use of AMD’s software was “very pleasant”
01:38PM EST – And finally, Lamini’s CEO, who has a PhD in Generative AI

01:39PM EST – Customers get to fully own their models
01:39PM EST – Imbuing LLNs with real knowledge
01:39PM EST – Had an AMD cloud in production for over the past year on MI210s/MI250s
01:40PM EST – Lamini has reached software parity with CUDA

01:41PM EST – Many of the genAI tools available today are open source
01:41PM EST – Many of them can run on ROCm today
01:43PM EST – AMD’s Instinct products are critical to supporting the future of business software

01:46PM EST – And that’s the mini-roundtable
01:47PM EST – Summing up the last 6 months of work on software
01:47PM EST – ROCm 6 shipping soon
01:47PM EST – 62K models running today, and more coming soon

01:48PM EST – And that’s a wrap for Victor Peng. Back to Lisa Su
01:49PM EST – And now for another guest spot: Meta
01:49PM EST – Ajit Mathews, Sr. Director of Engineering at Meta AI

01:50PM EST – Meta opened access to the Llama 2 model family in July
01:50PM EST – “An open approach leads to better and safer technology in the long-run”
01:51PM EST – Meta has been working with EPYC CPUs since 2019. And recently deployed Genoa at scale
01:51PM EST – But that partnership is much broader than CPUs

01:52PM EST – Been using the Instinct since 2020
01:53PM EST – And Meta is quite excited about MI300
01:53PM EST – Expanding their partnership to include Instinct in Facebook’s datacenters
01:53PM EST – MI300X is one of their fastest design-to-deploy projects

01:54PM EST – And Meta is pleased with the optimizations done for ROCm
01:55PM EST – (All of these guests are here for a reason: AMD wants to demonstate that their platform is ready. That customers are using it today and are having success with it)
01:55PM EST – Now another guest: Dell
01:56PM EST – Arthur Lewer, President of Core Business Operations for the Global Infrastrucutre Solutions Group

01:56PM EST – (Buying NVIDIA is the safe bet; AMD wants to demonstrate that buying AMD isn’t an unsafe bet)
01:57PM EST – Customers need a better solution than today’s ecosystem
01:58PM EST – Dell is announcing an update to the Poweredge 9680 servers. Now offering them with MI300X accelerators
01:58PM EST – Up to 8 accelerators in a box

01:58PM EST – Helping customers consolidate LLM training to fewer boxes
01:59PM EST – Ready to quote and taking orders today

02:01PM EST – And that’s Dell
02:02PM EST – And here’s another guest: Supermicro (we’ve now pivoted from cloud to enterprise)
02:02PM EST – Charles Liang, Founder, President, and CEO of Supermicro

02:03PM EST – Supermicro is a very important AMD server partner
02:05PM EST – What does Supermicro have planned for MI300X?
02:05PM EST – 8U air cooled system, and 4U system with liquid cooling
02:05PM EST – Up to 100kW racks of the latter

02:05PM EST – And that’s Supermicro
02:06PM EST – And another guest: Lenovo
02:06PM EST – Kirk Skaugen, President of Lenovo’s Infrastructure Solutions Group

02:07PM EST – Lenovo believes that genAI will be a hybrid approach
02:07PM EST – And AI will be needed at the edge
02:08PM EST – 70 AI-ready server and infrastructure products

02:09PM EST – Lenovo also has an AI innovators program for key verticals for simplifying things for customers
02:10PM EST – Lenovo thinks inference will be the dominate AI workload. Training only needs to happen once; inference happens all the time
02:11PM EST – Lenovo is bring MI300X to their ThinkSystem platform
02:11PM EST – And available as a service
02:12PM EST – And that’s Lenovo

02:13PM EST – And that’s still just the tip of the iceberg for the number of partners AMD has lined up for Mi300X

02:13PM EST – And now back to AMD with Forrest Norrod to talk about networking

02:14PM EST – The compute required to train the most advanced models has increased by leaps and bounds over the last decade
02:14PM EST – Leading AI clusters are tens-of-thousands of GPUs, and that will only increase
02:14PM EST – So AMD has worked to scale things up on multiple fronts
02:14PM EST – Internally with Infinity Fabric
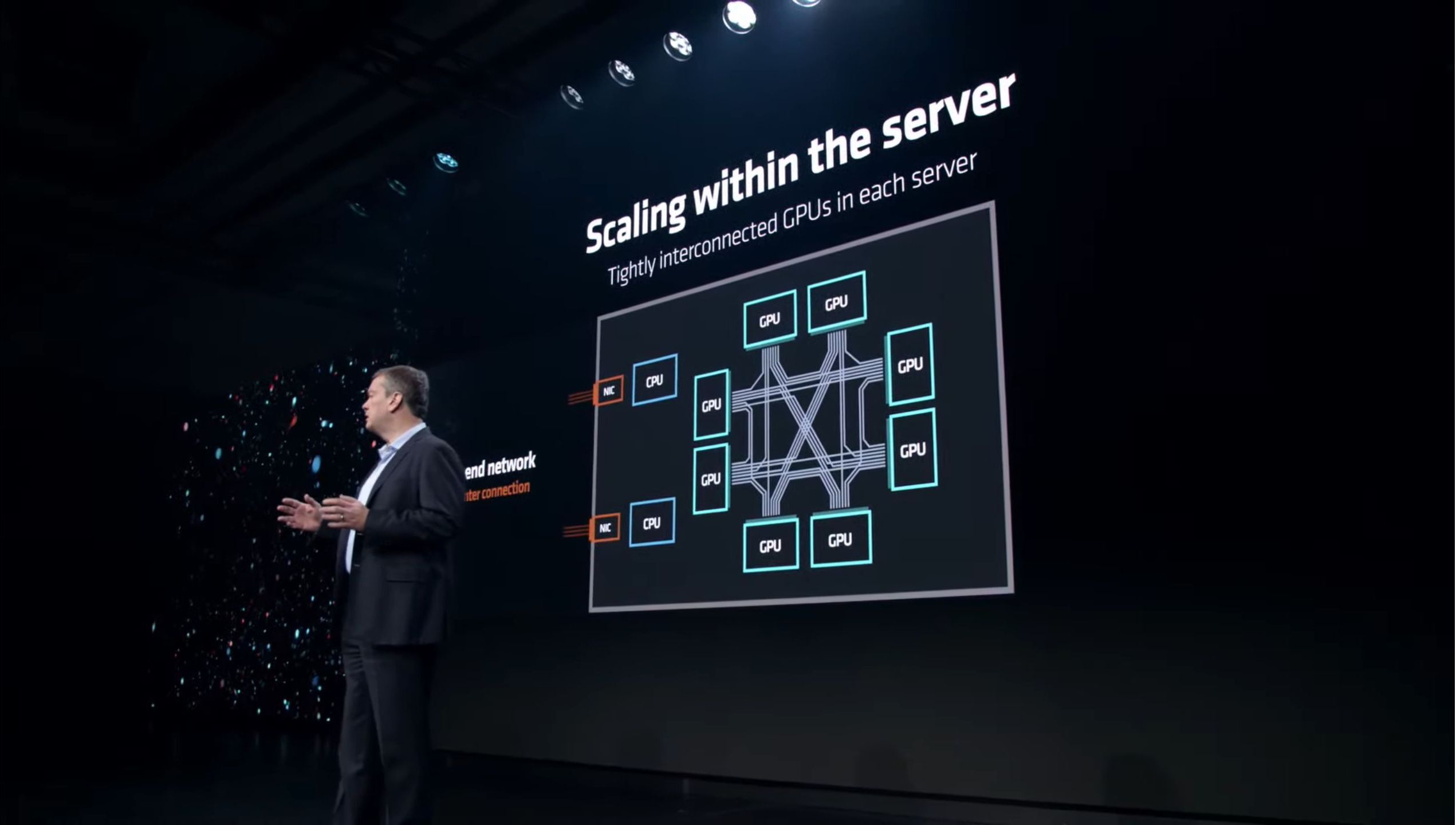
02:15PM EST – Near-linear scaling performance as you increase the number of GPUs
02:15PM EST – AMD is extending access to Infinity Fabric to innovators and strategic partners across the industry
02:15PM EST – We’ll hear more about this initiative next year
02:16PM EST – Meanwhile the back-end network connecting the servers together is just as critical
02:16PM EST – And AMD believes that network needs to be open

02:17PM EST – And AMD is backing Ethernet (as opposed to InfiniBand)

02:17PM EST – And Ethernet is open

02:18PM EST – Now coming to the stage are a few netowrking leaders, including Arista, Broadcom, and Cisco

02:19PM EST – Having a panel discussion on Ethernet

02:21PM EST – What are the advantages of Ethernet for AI?
02:22PM EST – Majority of hyperscalers are using Ethernet or have a high desire to
02:23PM EST – The NIC is critical. People want choices

02:24PM EST – “We need to continue to innovate”
02:24PM EST – AI networks need to be open standards based. Customers need choices
02:25PM EST – Ultra Ethernet is a critical next step
02:26PM EST – https://www.anandtech.com/show/18965/ultra-ethernet-consortium-to-adapt-ethernet-for-ai-and-hpc-needs

02:28PM EST – UEC is solving a very important technical problem of modern RDMA at scale
02:28PM EST – And that’s the networking panel

02:28PM EST – Now on to high-performance computing (HPC)
02:29PM EST – Recapping AMD’s experience thus far, including the most recent MI250X

02:29PM EST – MI250X + EPYC had a coherent memory space, but still the GPU and CPU separated by a somewhat slow link
02:29PM EST – But now MI300A is here with a unified memory system
02:29PM EST – Volume production began earlier this quarter

02:30PM EST – MI300 architecture, but with 3 Zen 4 CCDs layered on top of some of the IODs

02:31PM EST – 128GB of HBM3 memory, 4 IODs, 6 XCDs, 3 CCDs
02:31PM EST – And truly unified memory, as both GPU and CPU tiles go through the shared IODs

02:32PM EST – Performance comparisons with H100
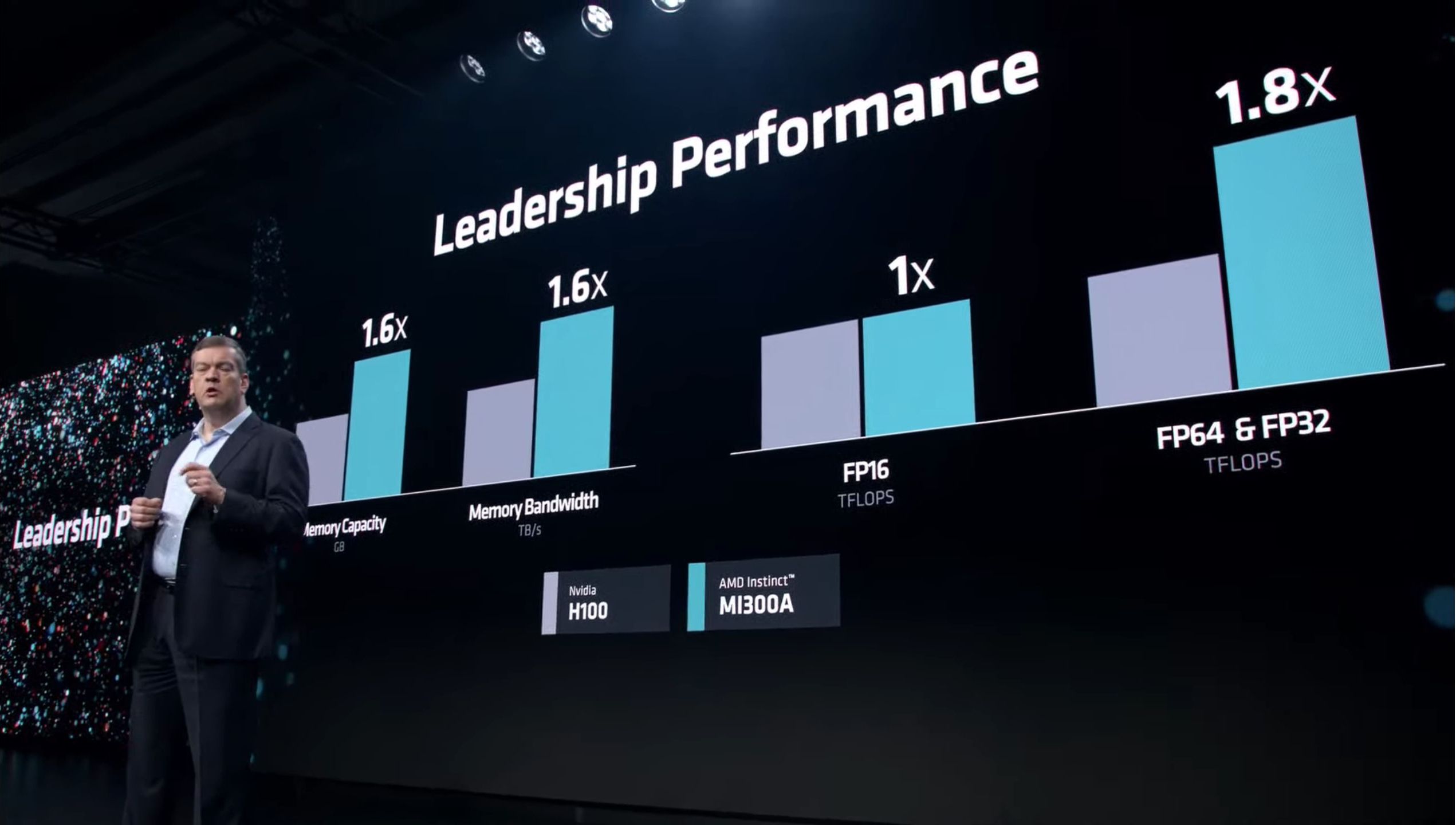
02:32PM EST – 1.8x the FP64 and FP32 (vector?) performance

02:33PM EST – 4x performnace on OpenFOAM with MI300A versus H100
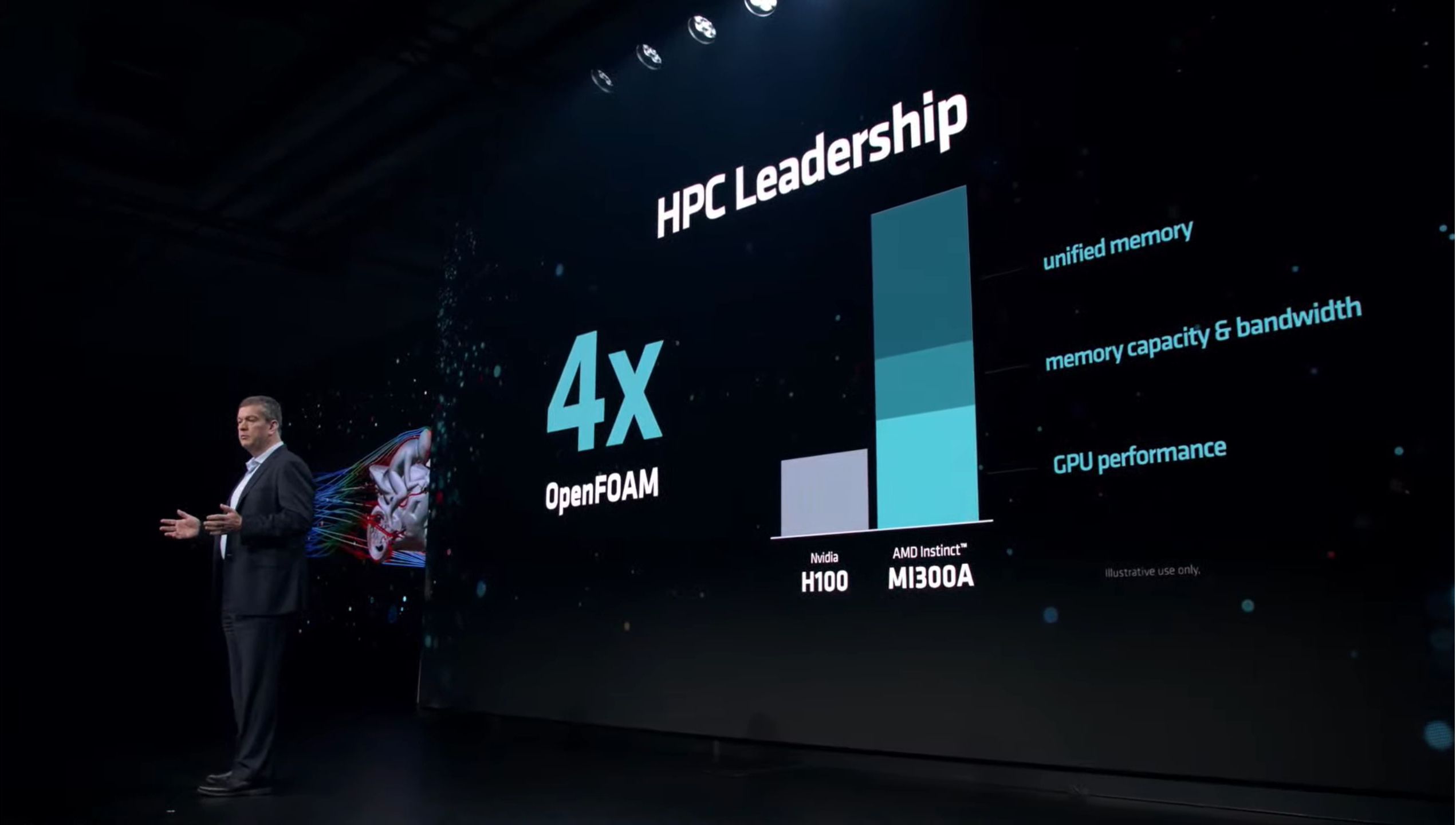
02:33PM EST – Most of the improvement comes from unified memory, avoiding having to copy around memory before it can be used
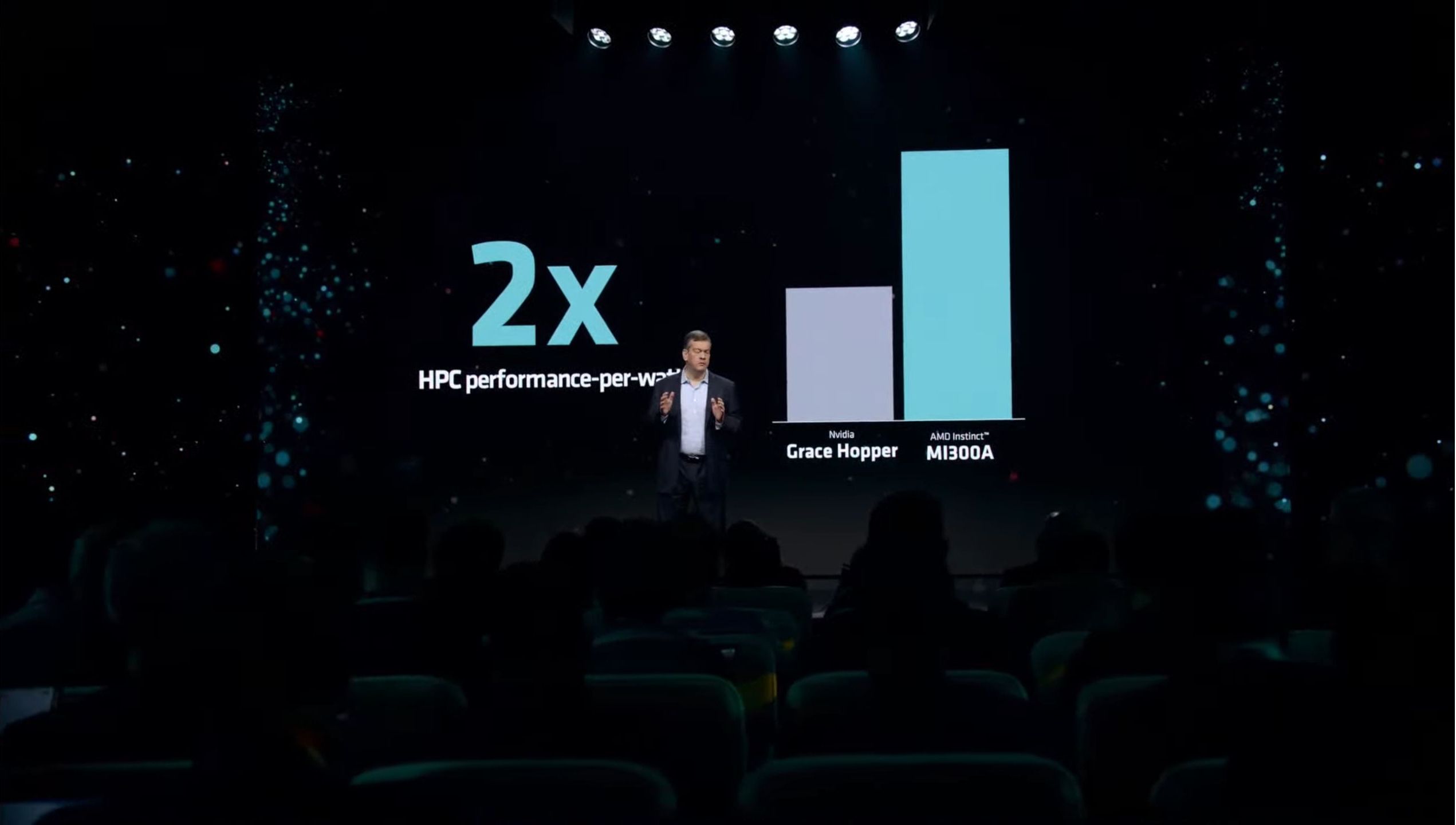
02:34PM EST – 2x the perf-per-watt than Grace Hopper (unclear by what metric)
02:35PM EST – MI300A will be in the El Capitan supercomputer. Over 2 EFLOPS of FP64 compute

02:35PM EST – Now rolling a video from HPE and the Lawrence Livermore National Lab
02:35PM EST – “El Capitan will be the most capable AI machine”

02:36PM EST – El Capitan will be 16x faster than LLNL’s current supercomputer
02:37PM EST – And now another guest on stage: HPE

02:37PM EST – Trish Damkroger, SVP and Chief Product Officer
02:38PM EST – Frontier was great. El Capitan will be even better
02:39PM EST – AMD and HPE power a large number of the most power efficient supercomputers

02:40PM EST – (Poor Forrest is a bit tongue tied)
02:40PM EST – ElCap will have MI300A nodes with SlingShot fabric
02:41PM EST – One of the most capable AI systems in the world
02:41PM EST – Supercomputing is the foundation needed to run AI

02:42PM EST – And that’s HPE
02:43PM EST – MI300A: A new level of high-performance leadership
02:43PM EST – MI300A systems avaialble soon from partners around the world
02:43PM EST – (So it sounds like MI300A is trailing MI300X by a bit)
02:43PM EST – Now back to Lisa
02:44PM EST – To cap off the day: Advancing AI PCs

02:44PM EST – AMD started including NPUs this year with the Ryzen Mobile 7000 series. The first x86 company to do so
02:44PM EST – Using AMD’s XDNA architecture

02:45PM EST – A large computing array that is extremely performant and efficient

02:45PM EST – Shipped millions of NPU-enabled PCs this year
02:46PM EST – Showing off some of the software applications out there that offer AI acceleration
02:46PM EST – Adobe, Windows studio effects, etc

02:46PM EST – Announcing Ryzen AI 1.0 software for developers
02:46PM EST – So AMD’s software SDK is finally available

02:47PM EST – Deploy tained and quantized models using ONNX
02:47PM EST – Announcing Ryzen Mobile 8040 series processors
02:47PM EST – Hawk Point

02:47PM EST – This is (still) the Phoenix die

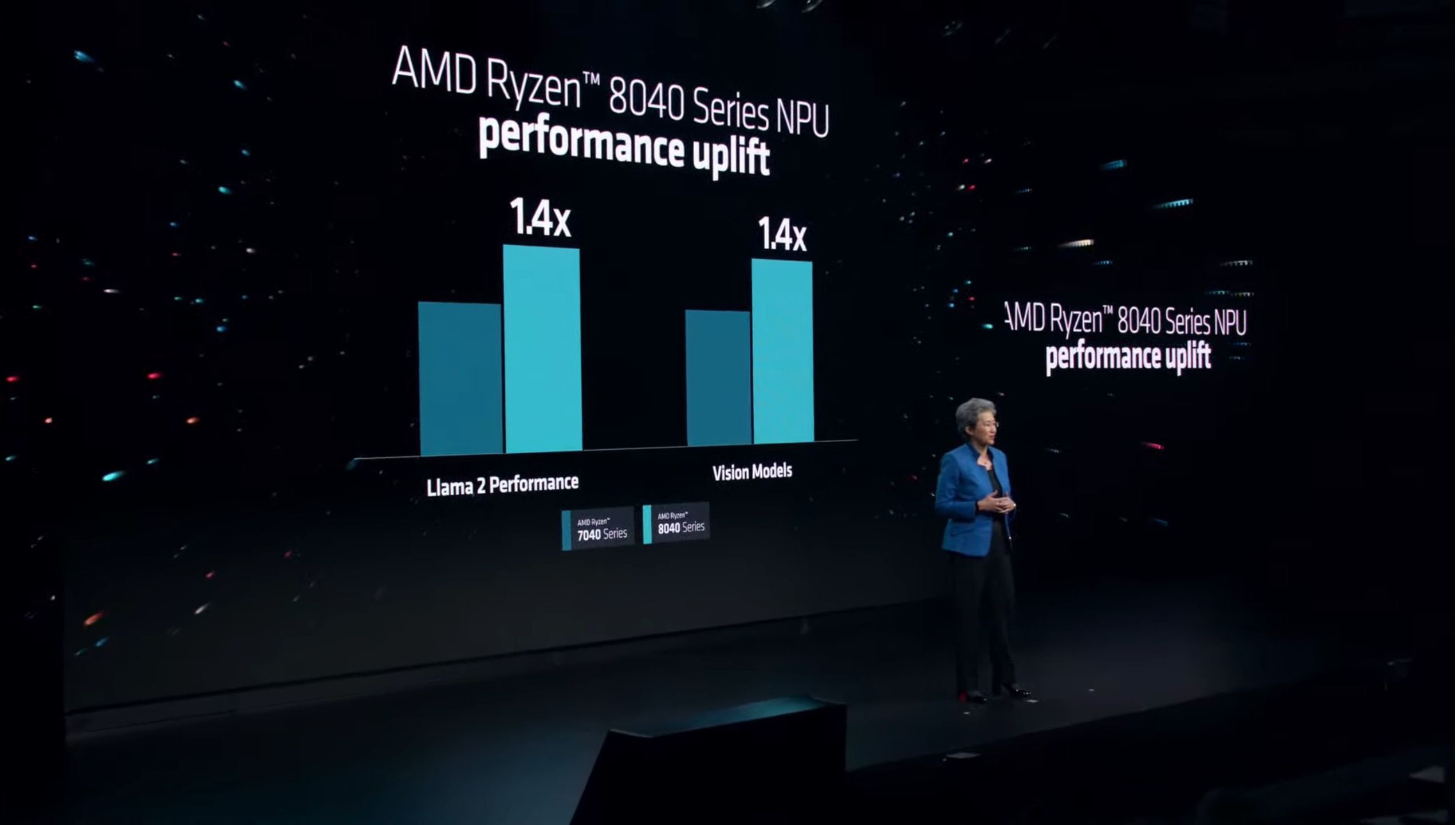
02:48PM EST – With one wrinkle: faster AI performance thanks to a higher clocked NPU
02:48PM EST – AMD’s own perf benchmarks show 1.4x over 7040 series
02:48PM EST – Now time for another guest: Microsoft
02:49PM EST – Pavan Davuluri, CVP for Windows and Devices
02:49PM EST – Talking about the work AMD and MS are doing together for client AI

02:50PM EST – Microsoft’s marquee project is Copilot

02:52PM EST – MS wants to be able to load-shift between the cloud and the client. Seamless computing between the two

02:52PM EST – Showing AMD’s NPU roadmap
02:53PM EST – Next-gen Strix Point processors in the works. Using a new NPU based on XDNA 2
02:53PM EST – Launching in 2024
02:53PM EST – XDNA 2 designed for “leadership” AI performance

02:53PM EST – AMD has silicon. So does MS
02:54PM EST – More than 3x the genAI perf (versus Hawk Point?)
02:55PM EST – And that’s AI on the PC
02:55PM EST – Now recapping today’s announcements

02:55PM EST – MI300X, shipping today. MI300A, in volume production
02:55PM EST – Ryzen Mobile 8040 Series, shipping now

02:56PM EST – “Today is an incredibly proud moment for AMD”

02:57PM EST – And that’s it for Lisa, and for today’s presentation
02:58PM EST – Thanks for joining us, and be sure to check out our expanded coverage of AMD’s announcements
02:58PM EST – https://www.anandtech.com/show/21177/amd-unveils-ryzen-8040-mobile-series-apus-hawk-point-with-zen-4-and-ryzen-ai
02:58PM EST – https://www.anandtech.com/show/21178/amd-widens-availability-of-ryzen-ai-software-for-developers-xdna-2-coming-with-strix-point-in-2024





