A bit over 5 years ago, Arm announced their Neoverse initiative for server, cloud, and infrastructure CPU cores. Doubling-down on their efforts to break into the infrastructure CPU market in a big way, the company set about an ambitious multi-year plan to develop what would become a trio of CPU core lineups to address different segments of the market – ranging from the powerful V series to the petite E series core. And while things have gone a little differently than Arm initially projected, they’re hardly in a position to complain, as the Neoverse line of CPU cores has never been as successful as it is now. Custom CPU designs based on Neoverse cores are all the rage with cloud providers, and the broader infrastructure market has seen its own surge.
Now, as the company and its customers turn towards 2024 and a compute market that is in the throes of another transformative change due to insatiable demand for AI hardware, Arm is preparing to release its next generation of Neoverse CPU core designs to its customers. And in the process, the company is reaching the culmination of the original Neoverse roadmap.
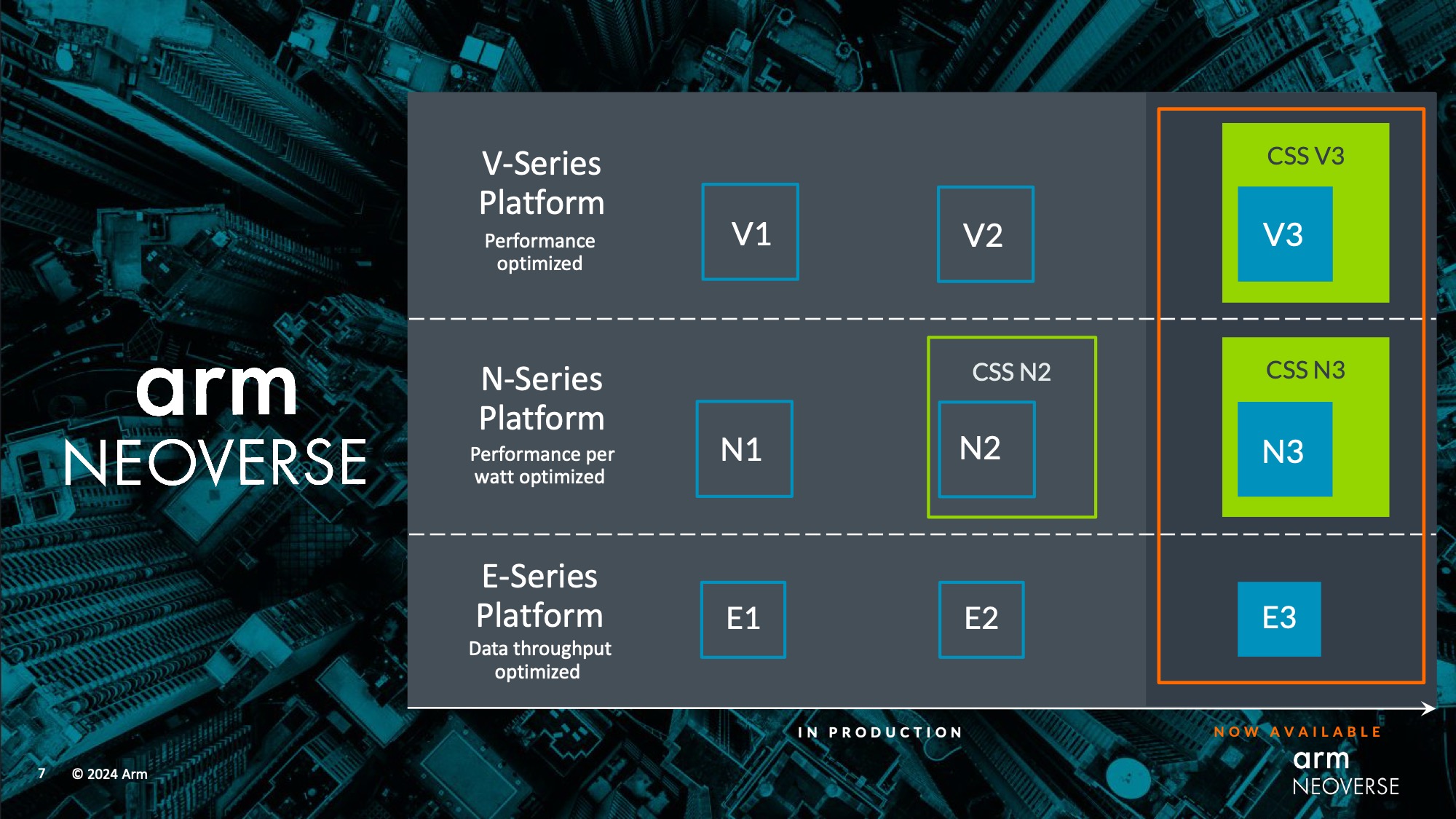
This morning the company is taking the wraps off of the V3 CPU architecture (codename Poseidon) for high-performance systems, as well as the N3 CPU architecture (codename Hermes) for balanced systems. These designs are now ready for customers to begin integrating into their own chip designs, with both the individual CPU core designs as well as the larger Compute Subsystems (CSS) available. Between the various combinations of IP configurations, Arm is looking to offer something for everyone, and especially chip designers who are looking to integrate ready-made IP for a quick turnaround in developing their own chips.
With that said, it should be noted that today’s announcement is also a lighter one than what we’ve come to expect from previous Neoverse announcements. Arm isn’t releasing any of the deep architectural details on the new Neoverse platforms today, so while we have the high-level details on the hardware and some basic performance estimates, the underlying details on the CPU cores and their related plumbing is something Arm is keeping to themselves until a later time.
Neoverse V3: Up To 128 Cores, with CXL 3.0 and HBM3, Plus a CSS Design
Starting things off with the high-end architecture of the Neoverse platform, the V3 CPU core. Previously listed in Arm’s roadmaps as “V-Next” and under its codename of Poseidon, the Neoverse V3 is the final architecture design in Arm’s original Neoverse roadmap, with Arm set to finally deliver on what they envisioned so long ago.
Neoverse V cores are traditionally derived from Cortex-X designs, and while Arm isn’t disclosing that level of detail today, there’s no reason to believe that’s changed. I suspect we’re looking at a CPU core design that borrows heavily from Cortex-X5 – Arm’s next-generation Cortex-X design – in keeping in line with the use of X1 and X3 for V1 and V2 respectively. But that is certainly a presumption on my part.
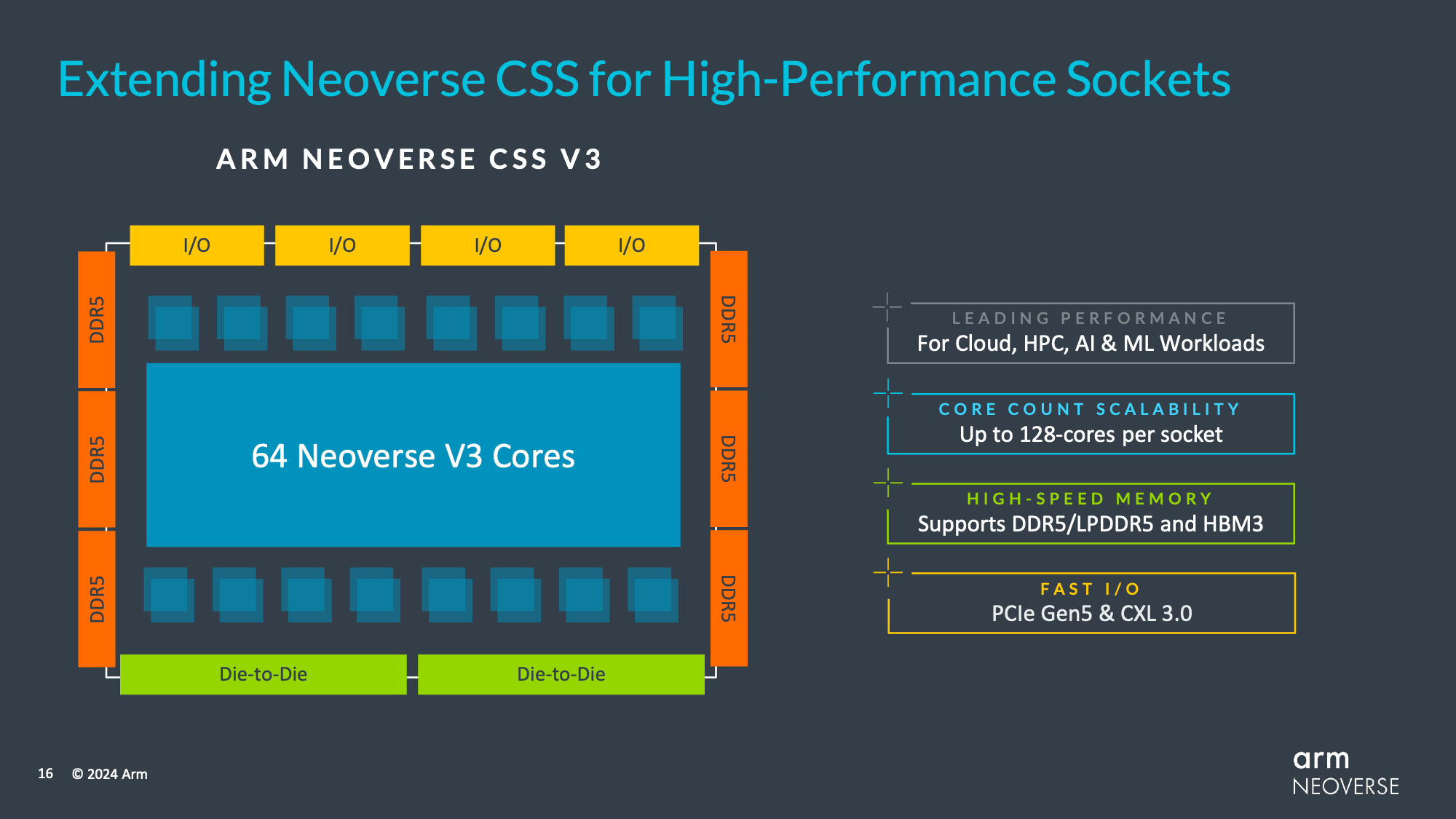
Regardless, like the previous V series CPU cores, the V3 is aimed at the highest-performance applications, delivering the highest single-threaded performance of any Arm Neoverse CPU core. And with up to 64 cores on a single die – and two dies/128 cores on a single socket – V3 is intended to compete at the high-end just like V2 did before it.
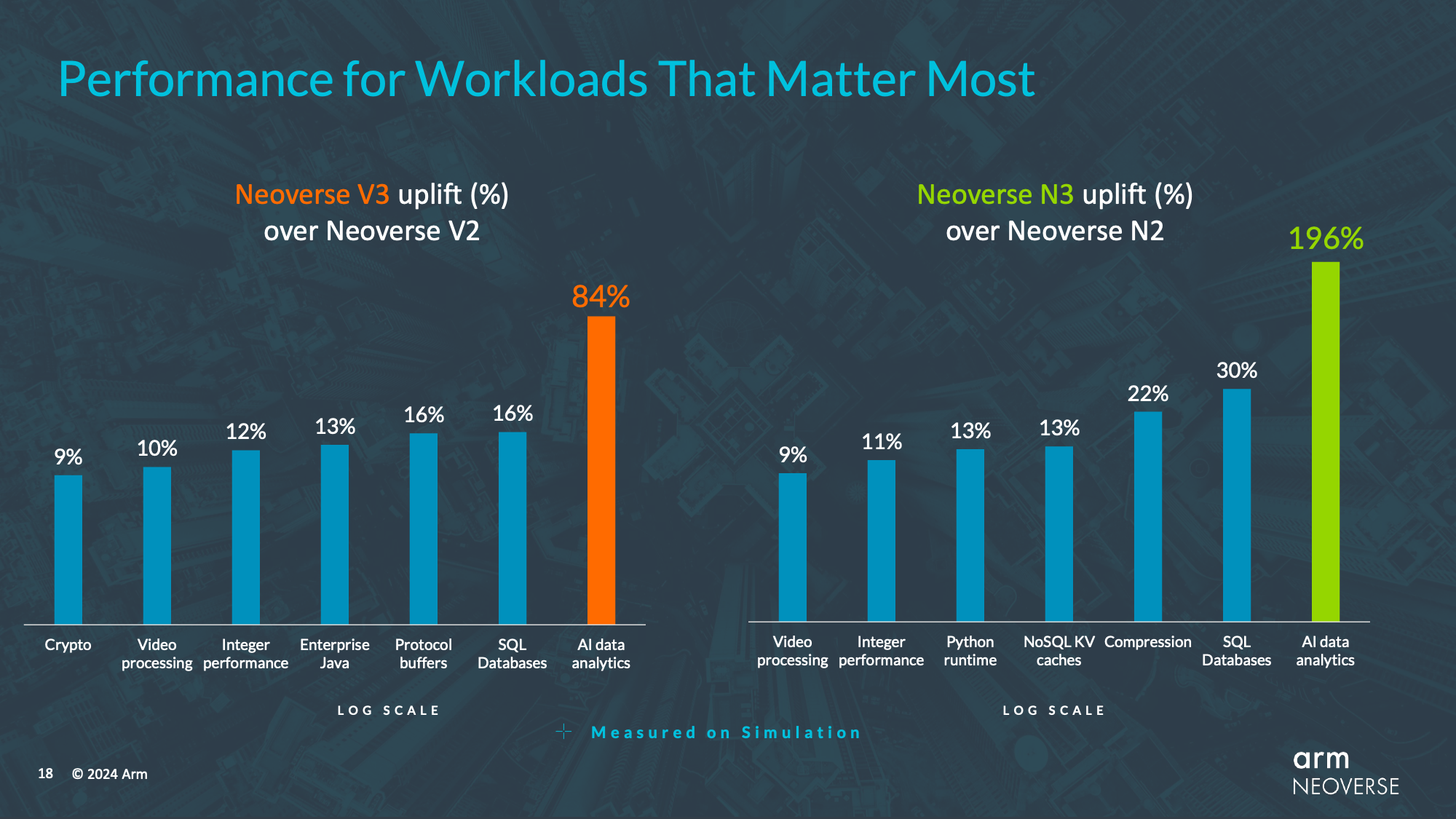
Arm has not provided a generalized performance estimate for the CPU core, but in simulations they’re seeing anywhere between 10% and 20% for most workloads, save the edge-case of AI data analytics (emphasis on the “analytics” and not the “AI”). Going back to Arm’s earliest roadmaps, this is lower than the 30% gen-on-gen improvements they were initially shooting for, but then again the V2 wasn’t even on those roadmaps at the time, so Arm’s steps have become smaller and a bit more frequent.
Again, we don’t have any deep-dive architectural details here, but we do have a few high-level details of the changes that come with V3. Arm has focused a good deal of their efforts on the mesh fabric at multiple points, for example. V3 itself has an improved how it connects to Arm’s mesh fabric in order to relieve pressure there. And the mesh fabric itself is new, replacing Arm’s tried-and-true CMN-700 with the new CMN-S3 – though we don’t have any further details on what the latter entails.
Otherwise, V3 and its CSS counterpart will come with support for all the latest I/O and memory formats. With I/O, CXL support has been bumped up from CXL 2.0 to CXL 3.0 – still sitting on top of PCIe 5.0. Meanwhile on the memory front, LPDDR5, DDR5, and HBM3 are all supported with Arm’s IP.
And for the first time for a V-series CPU core, Arm is offering an off-the-shelf CSS version of this IP for rapid integration into customer chip designs. Though the CSS initiative itself is still fairly new, Arm says that the strategy has proven very successful, with hungry, well-funded cloud service providers like Microsoft (Cobalt 100) rapidly adopting it in order to quickly get their own chip designs put together and hardware put into service. So Arm is looking to bring the same level of simplicity to high-performance customers, especially those who just need a proven CPU IP block to pair up with their custom accelerator designs – with Arm even providing a ready set of die-to-die connections to further streamline the process.
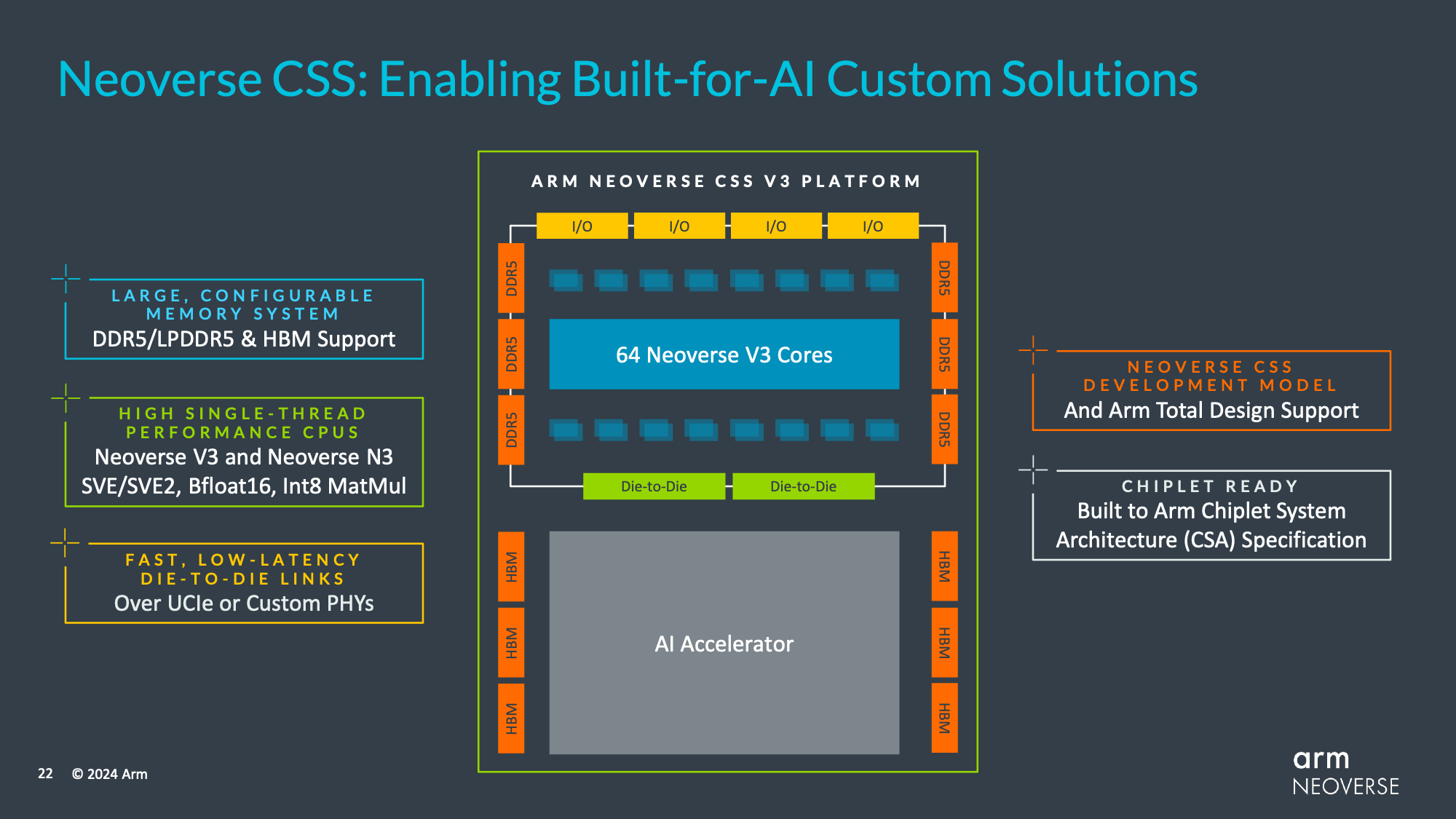
And while this was technically announced earlier this month, the V3 CSS design goes hand-in-hand with Arm’s efforts to establish their own chiplet ecosystem, the Arm Chiplet System Architecture (CSA). The CSA initiative is intended to allow customers to more easily mix and match chiplets in their products, with CSA going above and beyond just protocol compatibility and addressing things such as system management, DMA, security, and software compatibility.

Finally, underscoring the quick turnaround times that Arm is envisioning with the V3 CSS IP, the company is already announcing a design win with Socionext, who is designing a 32 core V3 CSS chiplet to be fabbed at TSMC.
Arm Neoverse N3: 20% Better Perf-Per-Watt, For Up to 32 Cores
The other half of today’s Neoverse IP announcement is Neoverse N3 (codename Hermes), the latest in Arm’s line of balanced, power-efficient CPU cores for a wide variety of markets.

With an even greater focus on their CSS IP this time around, the N3 CSS design supports a range of CPU cores, from 8 up to 32. In the case of the latter, Arm says that their design can operate as low as 40W TDP, or a bit over 1 Watt per CPU core – though the company isn’t disclosing on what process node this is.
Altogether, Arm is touting an average 20% performance-per-watt improvement for the N3 CSS over the N2 CSS. The overall performance improvements typically range between 10% and 30% depending on the specific workload.
Like V3, Arm isn’t offering much in the way of architectural details here. But with N-series designs historically sharing a good deal of design elements with the Cortex-A7xx series, I won’t be surprised to eventually find out it’s the same for the N3.
Meanwhile, Arm is providing a brief glimpse under the hood of N3 CSS to explain their big performance jump in AI data analytics, which is based around the XGBoost library.
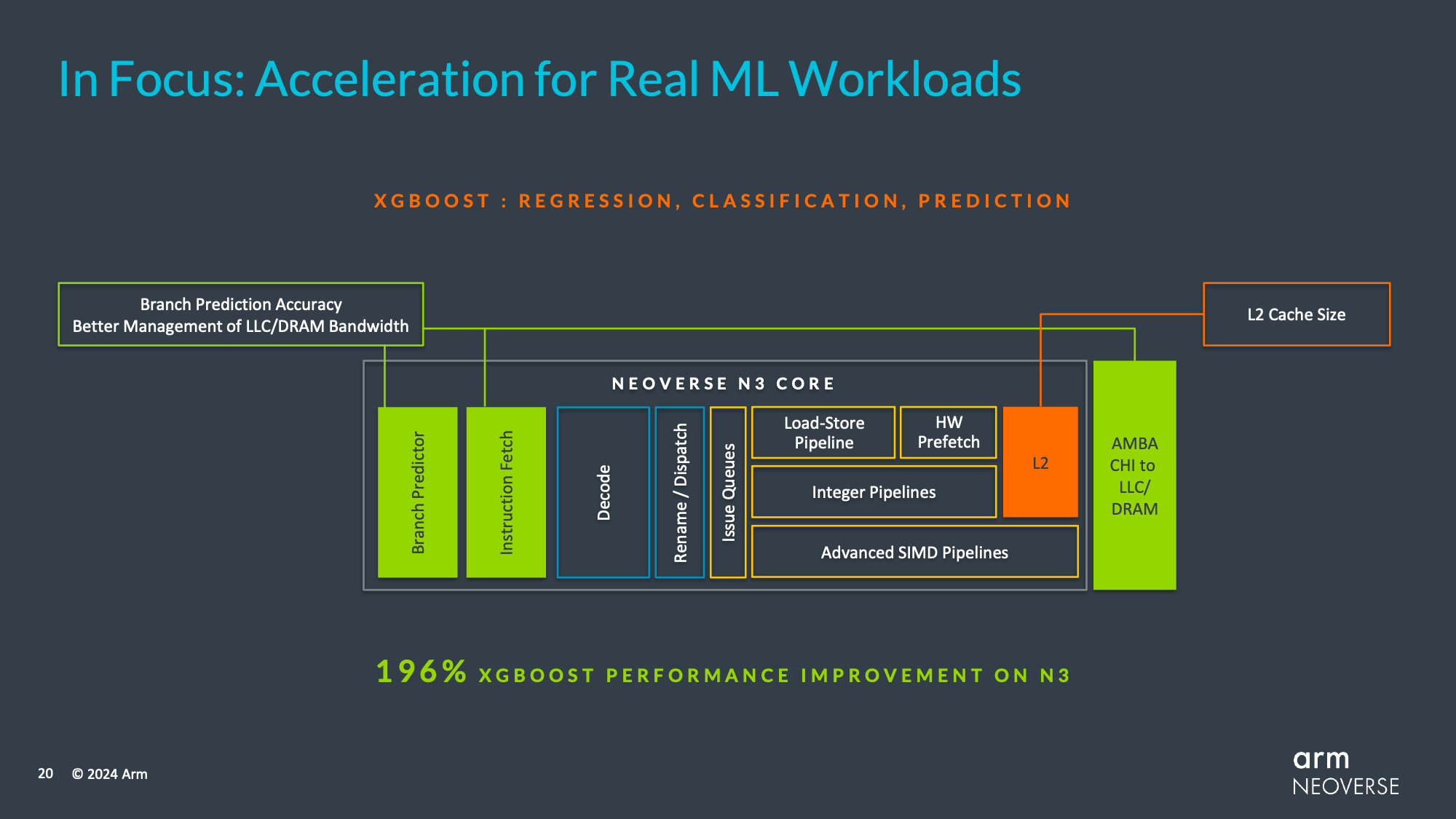
To start with, the L2 cache size for N3 CSS is now 2MB per core, up from 1MB for N2. In fact, Arm has also spent a fair bit of effort on their overall cache and memory subsystem, including making some undisclosed tweaks to their coherent host interface to better manage traffic and memory bandwidth between the CPU cores and last-level cache (and beyond). Though it is unclear of N3 is also using Arm’s new CMN-S3 mesh, or if that is limited to the V3. Meanwhile, on the front-end of the N3, the CPU core features an even more accurate branch prediction unit.
Altogether, these improvements and more are netting Arm a 196% improvement in XGBoost performance, and similarly the 84% performance improvement the V3 CPU core sees in the same workload. This makes data analytics/XGBoost an extreme outlier overall, but it does go to show where Arm has put some of their efforts with this upcoming generation of CPU architectures.
Outside of those core improvements, N3 also features many of the I/O and memory improvements that V3 also gets. Arm hasn’t provided an itemized list, but we’re told that it supports the latest PCIe and CXL standards – this presumably being PCIe 5.0 and CXL 3.0, respectively. Notably, Arm’s previous roadmap had this generation of hardware pegged to support PCIe 6.0, but with that not making it into the V3, it looks like Arm had to take a step back there.
Finally, like the V3 CSS, the N3 CSS also features a die-to-die interconnect. Though as with most other aspects of the N-series hardware, this has been scaled down to a single interconnect. So chip vendors can opt for integrating N3 directly into their die designs, or hooking it up to an external accelerator chiplet.
A Look Towards The Future: Adonis, Dionysus, and Lycius
Finally, as Arm has reached the end of their current Neoverse roadmap, the company is providing a roadmap for future CPU core releases.
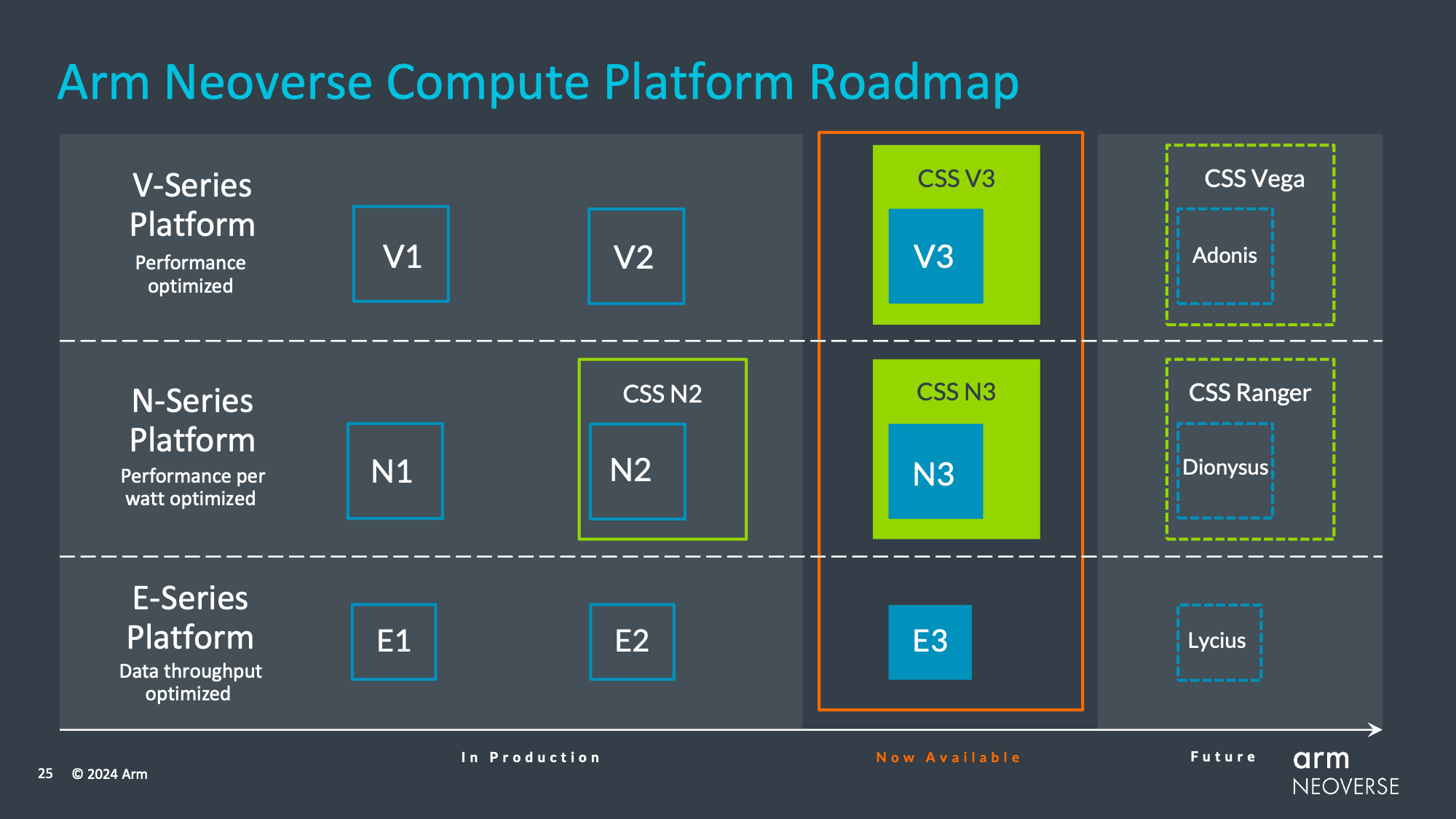
Notably here, this is a less detailed roadmap than Arm’s V2/N2-era roadmap, which included some high-level notes on what technologies were expected to be present. Instead, this roadmap provides codenames and little else.
Confirming that Arm is working on fourth-generation versions of the E, N, and V CPU cores, we have several new codenames overall. Lycius will be the next Neoverse E-series core (E4?), while Dionysus will be the next N-series core, and Adonis is the next V-series core. Meanwhile their respect compute subsystems are also getting codenames, with CSS Ranger and CSS Vega for the N-series CSS and V-series CSS respectively.
At this time Arm is not providing any guidance on when these designs will be ready for their customers. But with V3/N3 IP just going out the door to customers now, fouth generation Neoverse IP is likely a couple of years out.






{kind=link}